오늘은 연관관계 매핑에 대한 글입니다.
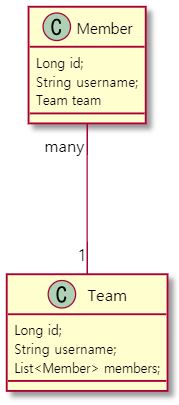
단순하게 Member 객체와 Team 객체가 있고 각각 id값을 설정 후 Member 객체 내부에 Team 객체를 참조할 수 있개 해줬고 반대인 경우도 해줬습니다.
Team 하나당 Member는 여러명이니까 Team 내부는 List로 선언했습니다.
Member 테이블을 만든다고 가정했을 때 PK 값은 member_id 팀 객체를 참조해야하니 team_id를 FK값으로 가지면 되겠네요.
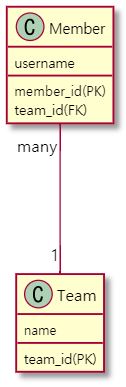
team_id가 Member 객체의 내부로 서로 연결되는 그림입니다.
현재 1 대 다 연관관계라고 볼 수 있는데 테이블은 PK와 FK 값만 알고 있으면 서로 연결시켜줄 수 있지만 객체 같은 경우는 그러지 못하죠.
어쨌든 그 객체를 품고있어야 합니다.
// MemberClass
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue(strategy = IDENTITY)
@Column(name="member_id")
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "team_id")
private Team team;
}
//TeamClass
@Entity
@Getter @Setter
public class Team{
@Id @GeneratedValue(strategy = IDENTITY)
@Column(name="team_id")
private Long id;
private String name;
@OneToMany(mapped by = "team")
private List<Member> members = new ArrayList<>();
}
strategy를 IDENTITY로 설정한 이유는 하이버네이트 버전의 기본 전략이 TABLE로 바뀌었더군요.
그래서 @GeneratedValue만 설정해주면 하나의 테이블에서 AUTO_INCREAMENT로 키 값을 관리하는 탓에 member_id에서 1번을 부여받으면 team_id는 2번을 부여받습니다.
테스트 코드 짤 때나 실행할 때나 크게 상관 없긴 하나 개인적으로 Member와 Team 각각 아이디 값이 증가하는게 좋을 거 같아 설정해뒀습니다.
코드에서 Member 입장에서는 Team을 볼 때 N : 1이라 볼수 있습니다. 그래서 @ManyToOne 입니다. 반대의 Team의 경우는 당연히 @OneToMany 겠지요.
여기서 중요한 건 @JoinColumn과 mapped by 입니다.
그림을 잘 보시면 선이 하나로 그어져있지만 객체 사이의 연관 관계는 사실 양방향이라기 보다는 단방향 두 개가 합쳐졌다고 봐야합니다
테이블 연관관계 같은 경우 FK를 통해 서로 왔다 갔다 할 수 있는 반면에 겍체는 테이블 같이 FK 하나만 가지고 서로 참조가 불가능하기 때문입니다.
즉
회원 » 팀 연관관계 1개
팀 » 회원 연관관계 1개
이라고 볼 수 있습니다.
이런 차이를 가지고 있기 때문에 이러한 객체를 테이블에 올바르게 매핑하려면 어찌됐든 하나의 객체가 이 FK를 관리해야합니다.
두 개의 객체가 동시에 FK를 관리한다는 것은 JPA입장에서도 모호성이 더해지기 때문이죠.
그럼 어떤 객체가 FK를 관리하는 것이 좋을까?
이런 경우에 대부분 FK를 가지고 있는 객체가 연관관계의 주인이 되는 것이 좋습니다.
위의 사진을 다시 보면 Member 객체가 Team의 외래키를 가지고 있습니다. 즉 Member 객체가 연관관계의 주인이 되는게 옳습니다.
그럼 Team은 어떻게 될까요?
연관관계의 주인이 아니기 때문에 단순히 Member 데이터에 대해 읽기만 가능합니다.
@ManyToOne
@JoinColumn(name = "team_id")
private Team team;
연관관계의 주인인 Member 객체에서 @JoinColumn의 name 값에 적혀있는 곳을 참조합니다.
@OneToMany(mapped by = "team")
private List<Member> members = new ArrayList<>();
연관관계의 주인이 아닌 Team 객체에는 mapped by를 써주고 그 뒤에 참조될 멤버 객체 내부에 있는 필드 값을 적어주면 됩니다.
여기서는 team이 되겠네요.
정리하면 연관관계의 주인에겐 @JoinColumn을 반대는 mapped by를 사용하면 됩니다.
연관관계의 주인을 정하는 방법은 다음 규칙을 따르는게 좋습니다.
-
연관관계가 1 대 N 일 경우 보통 N 쪽에 외래키를 참조하는 객체가 있다.
-
외래키를 가지는 객체가 연관관계의 주인이 되는 것이 좋다.
-
1번과 2번을 합치면 1 대 N 관계에서 N 부분에서 외래키를 관리하고 연관관계의 주인이 된다.
그럼 반대경우(여기서는 Team 객체)는 연관관계의 주인이 되면 안되는 건가?
라고 생각하실 수 있는데 할 수는 있습니다.
다만 이런 경우 상당히 헷갈리고 복잡해지기 시작합니다.
TEAM 테이블을 보시면 PK만 있지 외래키를 따로 관리하지는 않습니다. 여기서, 만약 JPA를 이용해서 연관관계의 주인으로 만들어버렸다고 칩시다.
이 경우 나는 분명히 Team의 members 값을 바꿨는데, 정작 업데이트 쿼리문은 FK가 있는 Member 객체로 나가게 됩니다.
자바 코드와 테이블이 서로 엇갈려버리는 것이죠.
그 외에도 단점들이 여러개 있긴 있지만 연관관계 매핑에 있어서 서로 엇갈려버리기 때문에 추후에 헷갈릴 가능성이 매우 높습니다.
그래서 어지간하면 FK를 관리하는 객체가 연관관계의 주인이 되는 것이 좋습니다!!
자 이제 객체를 연관관계를 통해서 서로 맺어줬으니 객체를 자유롭게 이동하는 것처럼 사용이 가능합니다.
package com.pra.shop.repository;
import com.pra.shop.domain.Member;
import com.pra.shop.domain.Team;
import org.assertj.core.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.annotation.Rollback;
import org.springframework.transaction.annotation.Transactional;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import java.util.List;
@SpringBootTest
@Transactional
class MemberRepositoryTest {
@PersistenceContext
EntityManager em;
@Test
@Rollback(value = false)
public void o(){
Member member = new Member();
Team team = new Team();
member.setName("kim");
team.setUsername("teamA");
member.setTeam(team);
team.getMembers().add(member);
em.persist(member);
em.persist(team);
Team team1 = em.find(Team.class, team.getId());//중요
List<Member> members = team1.getMembers();// 중요
System.out.println("=========");
members.stream().map(
a -> "memberName ::: " + a.getName())
.forEach(System.out::println);
System.out.println("=========");
Assertions.assertThat(members.size()).isEqualTo(1);
}
}
실제로 제가 테스트하기 위해 짠 코드입니다. 간단하게 하려고 했는데 단계별로 보여주려니 코드가 길어졌네요
위 코드에서 중요한 부분을 따로 주석으로 달았습니다. 단순히 객체를 테이블에 맞게 매핑시켰다고 바로 사용할 수 있는게 아니라 반드시 서로 연관관계를 맺어주셔야 이동이 가능합니다.
위 코드에서는 [//중요]라고 해놓은 두 줄이 되겠네요.
보시다시피 team과 member 객체에 각각 연관관계를 맺어주고 있습니다.
이렇게 연관관계를 맺어준 뒤에 비로소 team1에 있는 멤버 리스트를 뽑아서 각각 멤버의 이름을 알 수 있는 것이죠.
현재 넣은 데이터가 “kim” 밖에 없으니 당연히 사이즈는 1 입니다.
2020-11-04 17:40:52.009 TRACE 16056 --- [ Test worker] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [VARCHAR] - [teamA]
=========
memberName ::: kim
=========
2020-11-04 17:40:52.094 DEBUG 16056 --- [ Test worker] org.hibernate.SQL
디버그 코드를 보시면 memberName이 kim으로 나오는 것을 볼 수 있습니다.
사실 코드를 짜는 것이 사람인지라 연관관계를 서로 맺어주는 코드를 하나만 설정하고 나머지를 까먹는 경우가 종종 있습니다.
이런 경우에 Setter 메서드에 연관관계 편의 메서드를 만들어 주곤 합니다. 이렇게요.
public void setTeam(Team team){
this.team = team;
team.getMembers().add(this);
}
이 코드가 멤버 클래스에 있으면, 단순히 member.setTeam을 호출하는 것만으로 서로 연관관계를 맺을 수 있습니다.
만약 Team에 편의 메서드를 구현한다면
public void addMember(Member member){
member.setTeam(this);
members.add(member);
}
다음과 같이 되겠네요. Team 객체에는 Member 객체가 없으므로 따로 addMember 메서드를 만들었습니다.
중요한 것은 연관관계 편의 메서드는 한 곳에만 있어야지 두 곳에 모두 있으면 에러가 생길 수도 있으므로 주의하시길 바랍니다.